2025-03-02 16:46:36,844 INFO job_manager.py:530 -- Runtime env is setting up.
2025-03-02 16:46:38,772 INFO worker.py:1514 -- Using address 10.244.0.32:6379 set in the environment variable RAY_ADDRESS
2025-03-02 16:46:38,772 INFO worker.py:1654 -- Connecting to existing Ray cluster at address: 10.244.0.32:6379...
2025-03-02 16:46:38,779 INFO worker.py:1832 -- Connected to Ray cluster. View the dashboard at 10.244.0.32:8265
View detailed results here: /home/ray/ray_results/TorchTrainer_2025-03-02_16-46-38
To visualize your results with TensorBoard, run: `tensorboard --logdir /tmp/ray/session_2025-03-02_16-41-01_620759_1/artifacts/2025-03-02_16-46-38/TorchTrainer_2025-03-02_16-46-38/driver_artifacts`
Training started without custom configuration.
(RayTrainWorker pid=1782, ip=10.244.0.33) Setting up process group for: env:// [rank=0, world_size=2]
(TorchTrainer pid=1710, ip=10.244.0.33) Started distributed worker processes:
(TorchTrainer pid=1710, ip=10.244.0.33) - (node_id=5b33327eef2d53d0fb66159600c869156d1704dfe6bed2216c6d6a0d, ip=10.244.0.33, pid=1782) world_rank=0, local_rank=0, node_rank=0
(TorchTrainer pid=1710, ip=10.244.0.33) - (node_id=b3fa06e1bdd598ac862356b874c4bcae5073ba592048f24ef99e4d59, ip=10.244.0.32, pid=3933) world_rank=1, local_rank=0, node_rank=1
(RayTrainWorker pid=1782, ip=10.244.0.33) Moving model to device: cuda:0
(RayTrainWorker pid=1782, ip=10.244.0.33) Wrapping provided model in DistributedDataParallel.
Training finished iteration 1 at 2025-03-02 16:48:28. Total running time: 1min 49s
╭───────────────────────────────╮
│ Training result │
├───────────────────────────────┤
│ checkpoint_dir_name │
│ time_this_iter_s 2.07639 │
│ time_total_s 2.07639 │
│ training_iteration 1 │
│ loss 1.1731 │
╰───────────────────────────────╯
Training finished iteration 2 at 2025-03-02 16:48:28. Total running time: 1min 49s
╭───────────────────────────────╮
│ Training result │
├───────────────────────────────┤
│ checkpoint_dir_name │
│ time_this_iter_s 0.00212 │
│ time_total_s 2.07851 │
│ training_iteration 2 │
│ loss 1.15955 │
╰───────────────────────────────╯
Training finished iteration 3 at 2025-03-02 16:48:28. Total running time: 1min 49s
╭───────────────────────────────╮
│ Training result │
├───────────────────────────────┤
│ checkpoint_dir_name │
│ time_this_iter_s 0.00126 │
│ time_total_s 2.07977 │
│ training_iteration 3 │
│ loss 1.14664 │
╰───────────────────────────────╯
Training finished iteration 4 at 2025-03-02 16:48:28. Total running time: 1min 49s
╭───────────────────────────────╮
│ Training result │
├───────────────────────────────┤
│ checkpoint_dir_name │
│ time_this_iter_s 0.00129 │
│ time_total_s 2.08106 │
│ training_iteration 4 │
│ loss 1.13435 │
╰───────────────────────────────╯
Training finished iteration 5 at 2025-03-02 16:48:28. Total running time: 1min 49s
╭───────────────────────────────╮
│ Training result │
├───────────────────────────────┤
│ checkpoint_dir_name │
│ time_this_iter_s 0.00167 │
│ time_total_s 2.08273 │
│ training_iteration 5 │
│ loss 1.12264 │
╰───────────────────────────────╯
Training finished iteration 6 at 2025-03-02 16:48:28. Total running time: 1min 49s
╭───────────────────────────────╮
│ Training result │
├───────────────────────────────┤
│ checkpoint_dir_name │
│ time_this_iter_s 0.01947 │
│ time_total_s 2.1022 │
│ training_iteration 6 │
│ loss 1.1115 │
╰───────────────────────────────╯
Training finished iteration 7 at 2025-03-02 16:48:28. Total running time: 1min 49s
╭───────────────────────────────╮
│ Training result │
├───────────────────────────────┤
│ checkpoint_dir_name │
│ time_this_iter_s 0.00117 │
│ time_total_s 2.10337 │
│ training_iteration 7 │
│ loss 1.10089 │
╰───────────────────────────────╯
Training finished iteration 8 at 2025-03-02 16:48:28. Total running time: 1min 49s
╭───────────────────────────────╮
│ Training result │
├───────────────────────────────┤
│ checkpoint_dir_name │
│ time_this_iter_s 0.00124 │
│ time_total_s 2.1046 │
│ training_iteration 8 │
│ loss 1.09079 │
╰───────────────────────────────╯
Training finished iteration 9 at 2025-03-02 16:48:28. Total running time: 1min 49s
╭───────────────────────────────╮
│ Training result │
├───────────────────────────────┤
│ checkpoint_dir_name │
│ time_this_iter_s 0.00122 │
│ time_total_s 2.10582 │
│ training_iteration 9 │
│ loss 1.08118 │
╰───────────────────────────────╯
Training finished iteration 10 at 2025-03-02 16:48:28. Total running time: 1min 49s
╭───────────────────────────────╮
│ Training result │
├───────────────────────────────┤
│ checkpoint_dir_name │
│ time_this_iter_s 0.00132 │
│ time_total_s 2.10715 │
│ training_iteration 10 │
│ loss 1.07202 │
╰───────────────────────────────╯
Training completed after 10 iterations at 2025-03-02 16:48:29. Total running time: 1min 50s
2025-03-02 16:48:29,431 INFO tune.py:1009 -- Wrote the latest version of all result files and experiment state to '/home/ray/ray_results/TorchTrainer_2025-03-02_16-46-38' in 0.0022s.
Final loss: 1.0720233917236328
Processed data: [0, 2, 4, 6, 8, 10, 12, 14, 16, 18]
(RayTrainWorker pid=3933) Moving model to device: cuda:0
(RayTrainWorker pid=3933) Wrapping provided model in DistributedDataParallel.
Barebone deployments at work
I finally had some time this weekend to deploy ray framework in my home Infra. I’ve become a huge fan of Ray framework over the last ~6 months after setting it up and maintaining it primarily at my work. I deployed Ray on barebone GCP Compute Instances through Iaac and it’s been working pretty well.
The current workflow I’ve setup at my work is a ray cluster per use case/tenant hosted in my team’s GCP project.
A typical sizing of this setup for a larger use case will look like this…
Machine Type: a2-highgpu-4g
GPUs: 4× NVIDIA A100 (40GB or 80GB HBM2)
vCPUs: 48
RAM: 336 GBresource "google_compute_instance" "uc_xxxx_a100" {
name = "uc-xxxx-a100"
machine_type = "a2-highgpu-4g"
zone = "us-central1-a"
guest_accelerator {
type = "nvidia-tesla-a100"
count = 4
}
scheduling {
on_host_maintenance = "TERMINATE"
}
boot_disk {
initialize_params {
image = "projects/deeplearning-platform-release/global/images/family/common-cu113"
size = 200
}
}
network_interface {
network = "default"
access_config {}
}
}or in the case of smaller use cases…
Machine Type: n1-standard-16
GPUs: 4× NVIDIA T4 (16GB GDDR6)
vCPUs: 16
RAM: 60 GBresource "google_compute_instance" "uc_xxxx_t4" {
name = "uc-xxxx-t4"
machine_type = "a2-highgpu-4g"
zone = "us-central1-a"
guest_accelerator {
type = "nvidia-tesla-t4"
count = 4
}
scheduling {
on_host_maintenance = "TERMINATE"
}
boot_disk {
initialize_params {
image = "projects/deeplearning-platform-release/global/images/family/common-cu113"
size = 200
}
}
network_interface {
network = "default"
access_config {}
}
}This setup allows to train and run inferences with minimal latencies which is always desired.
Apart from this, I’ve also setup standard templates for bringing up Vertex AI workbenches using Gitlab runners to setup experiments. This has evolved and has become the standard for my team to onboard new tenants that’s building POCs now.
Setting up my personal workflow
Personally, I run a two node production k8s along with my home servers which I mainly use for serving and testing cloud native apps, and I wanted to use it for deploying ray to quickly scale my scratch training scripts to cloud instances.
I spent most of today setting this up with Grafana-Loki stack additionally for better observability.
To test this setup, I also rented 12 nodes from Hetzner and scaled it into a multi-node, multi-GPU configuration. Performance was impressive across all my tests given the expected node latencies of course.
The code for this deployment will be made available in the ray-infra-test repo on my github.
Test scripts
I’ve included a training script (defaulting to 2 gpus) to test a ray multi GPU training job in the ray cluster.
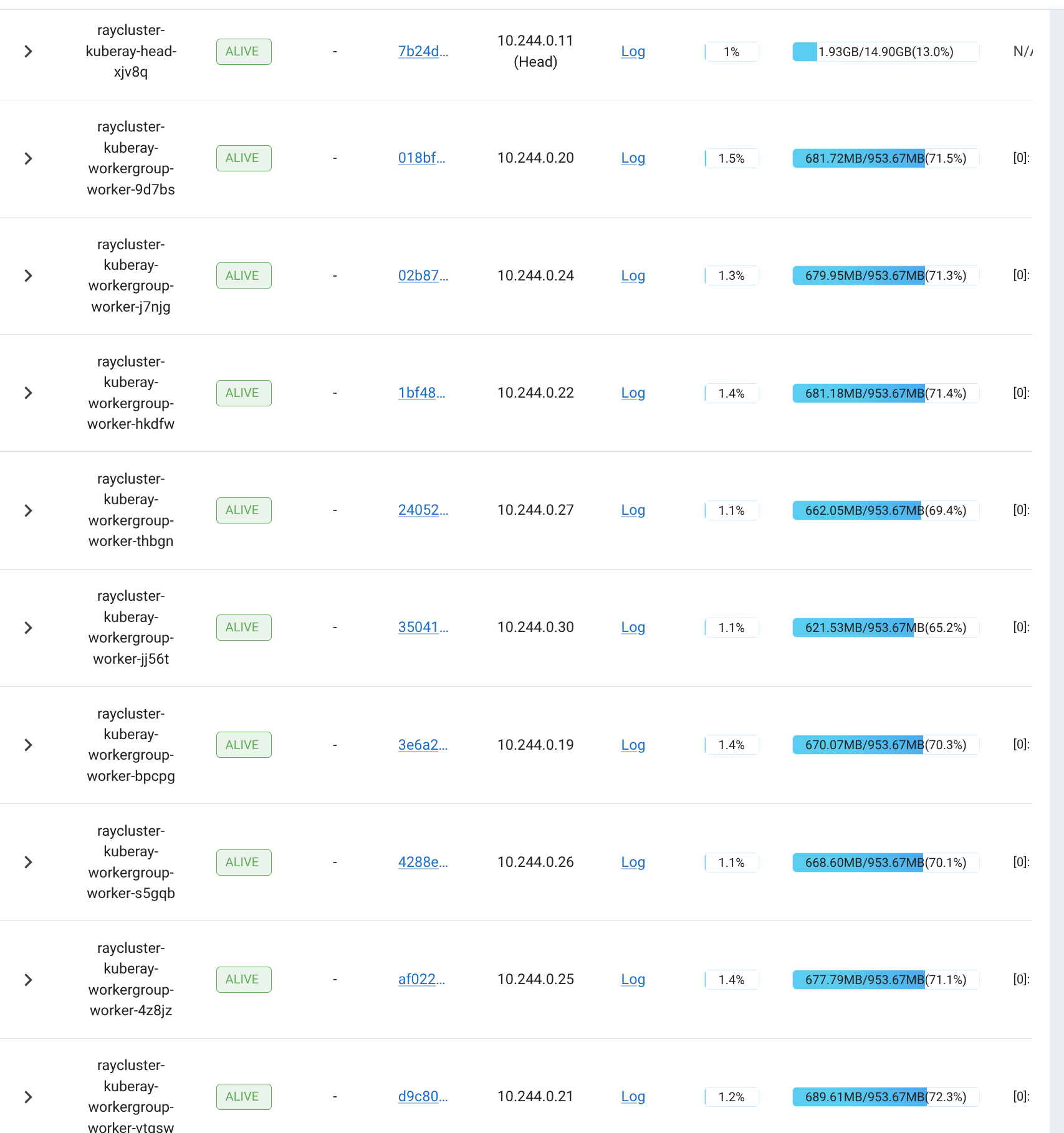
If the setup is correct like mine, then looking at the cluster information should show GPUs with high utilization.
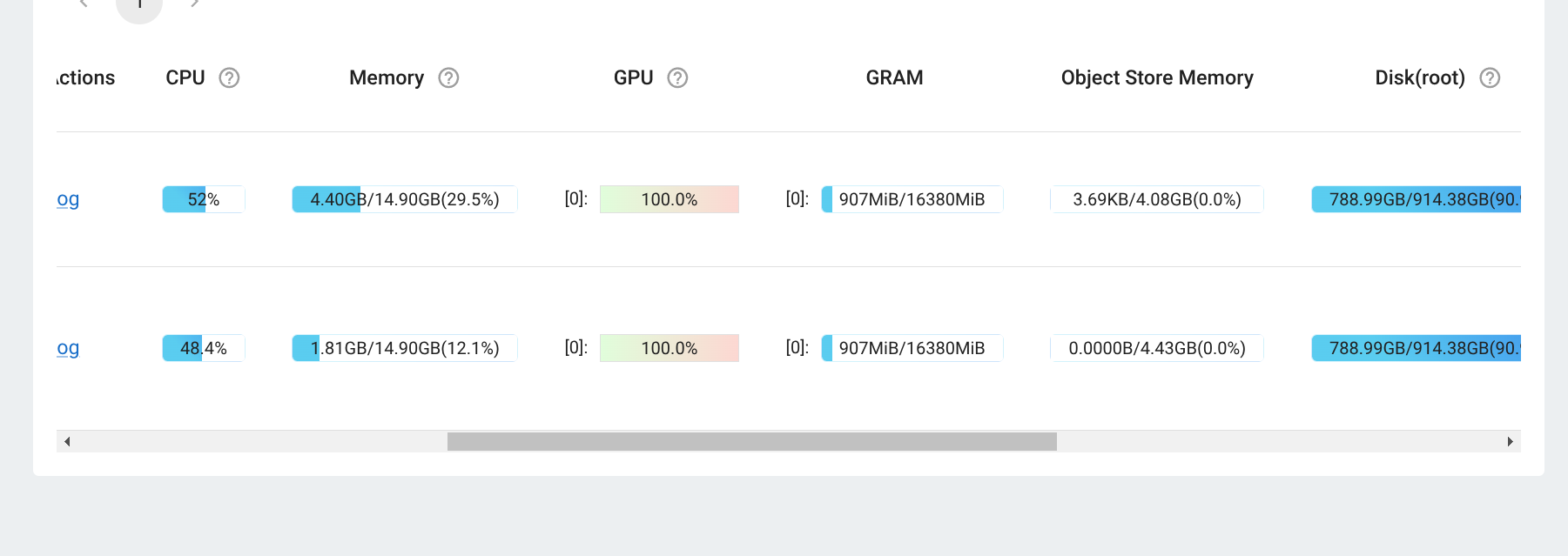
And the same can be verified by looking at the training log where it sets up the training with DistributedDataParallel across two GPUs.
cat ob-driver-raysubmit_LRqs7C497Z5M1qDQ.logI stream the cluster and job metrics into Loki which I can then query and analyze more thorughly when I need to debug the training jobs.
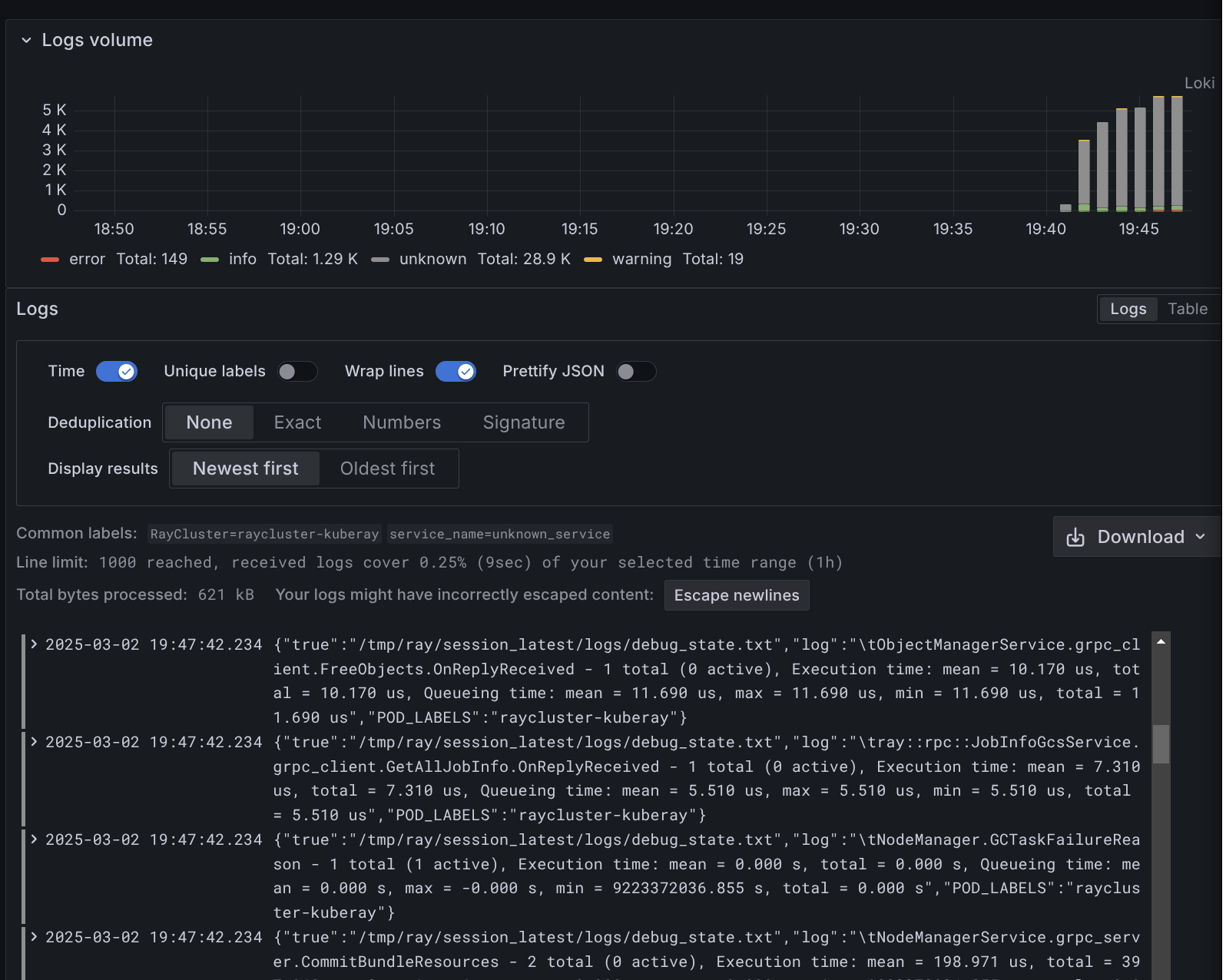
Overall, I am pretty happy with how this setup is working so far from my tests and it should be super helpful for me to quickly scale up my training!
My next plan is to try adding New Relic into this setup. I’ve been following New Relic for some time now and their integrations look really interesting. Stay tuned for more updates on this!